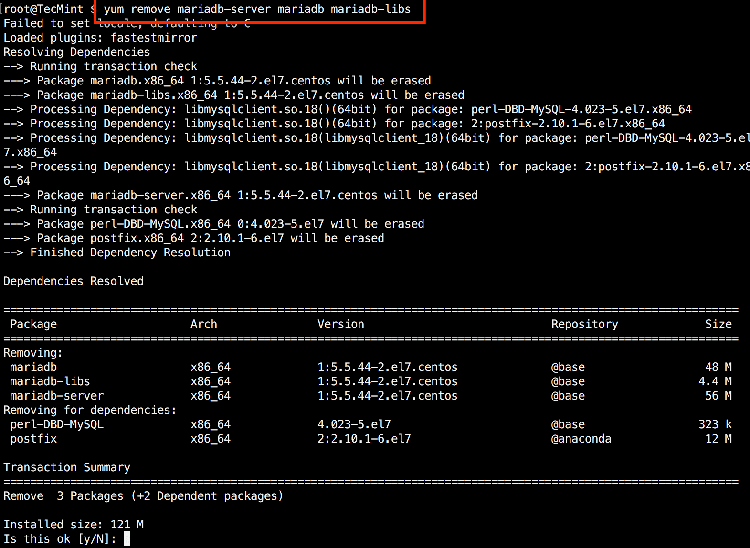
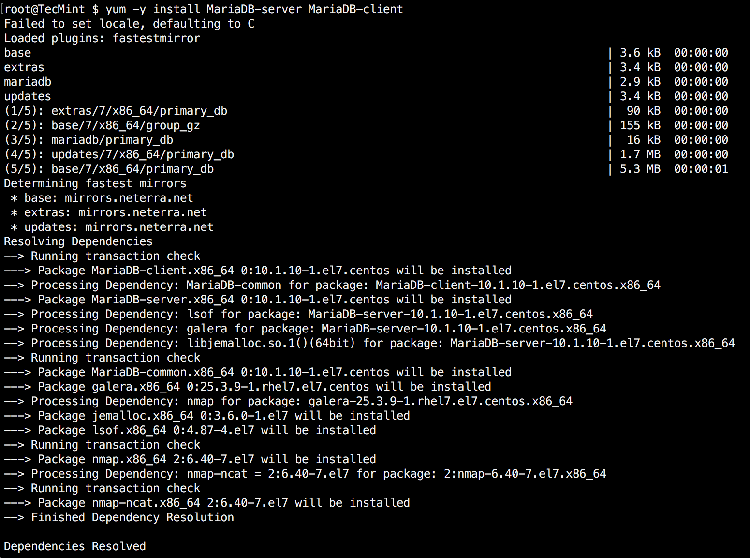
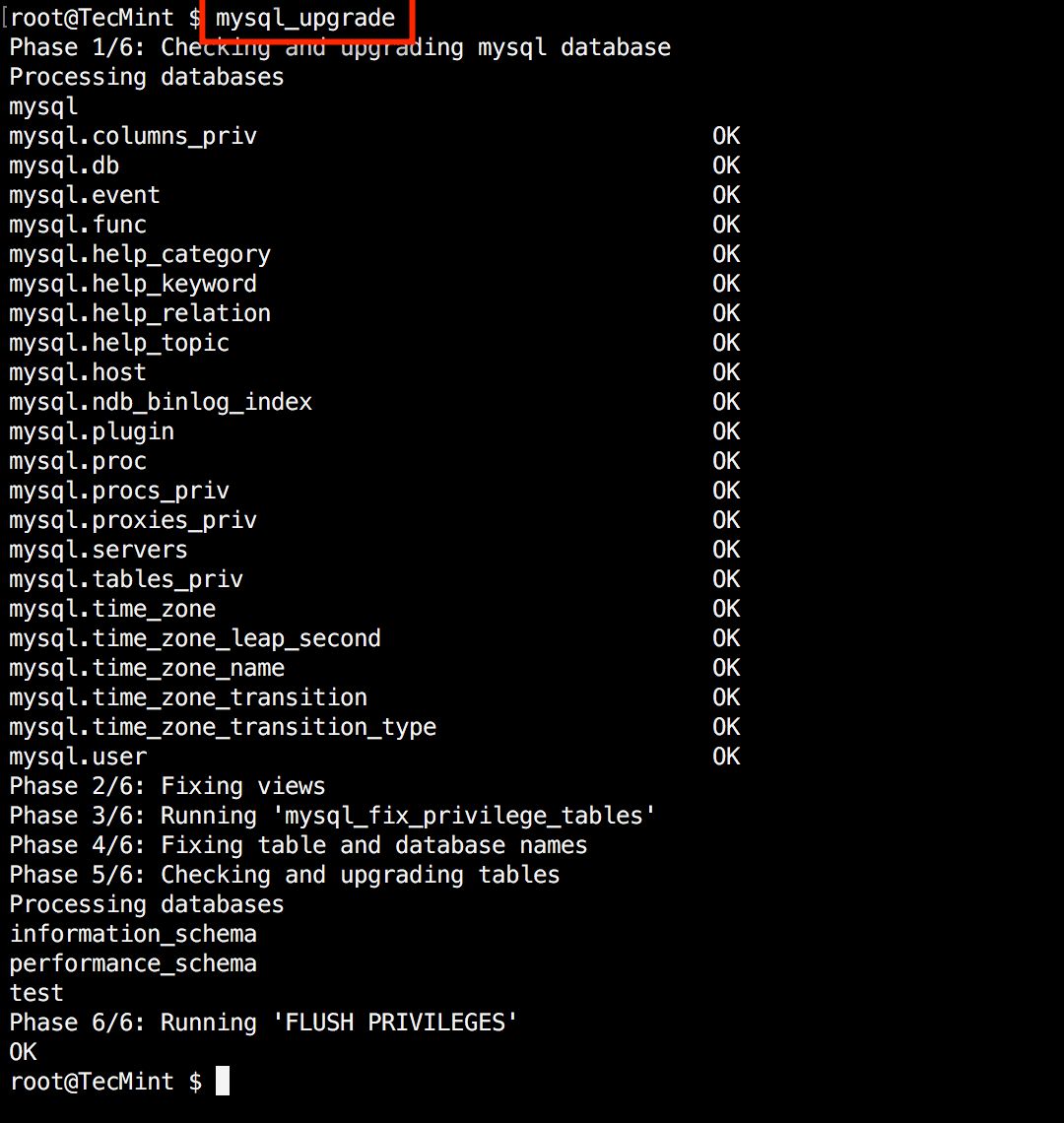
make my.cnf
make my.cnf file as mysvc01 user.
my.cnf : The file has system variables for DB environment.
location of MariaDB SW in this docoment : /engn001/mysvc01/mariadb-10.0.26
location of my.cnf in this document: /engn001/mysvc01/MARIASVC/my.cnf
my.cnf sample
$ vi /engn001/mysvc01/MARIASVC/my.cnf
##---------------------------------------------------------------------------
## Author: YJ
## mysqld 데몬 프로세스 관련 설정들
##---------------------------------------------------------------------------
[mysqld]
core-file # core dump 파일을 생성하도록 하기 위한 설정
user = mysvc01 # MariaDB 엔진의 owner (user id) = DB를 실행시킬 OS 계정
port = 3306 # DB 포트
socket = /engn001/mysvc01/MARIASVC/mysqld.sock # 소켓파일 경로(로컬서버 접속에 사용), 리모트 서버에는 ip와 port를 이용해서 TCP/IP 프로토콜로 접근
pid-file = /engn001/mysvc01/MARIASVC/mysqld.pid # MariaDB 서버가 자신의 프로세스 ID를 기록하는 파일 경로 (유닉스 혹은 리눅스에서만 사용)
basedir = /engn001/mysvc01/mariadb-10.0.26 # MariaDB 엔진 경로
datadir = /data001/mysvc01/MARIASVC # DB의 데이터가 생성될 기본 경로
tmpdir = /data001/mysvc01/tmpdir_MARIASVC # 디스크에 임시테이블이 생성될 때 사용될 경로
#secure_file_priv = /tmp # LOAD_FILE() 함수 및 LOAD DATA 와 SELECT ... INTO OUTFILE 명령문이 특정 디렉토리에 있는 파일에서만 동작을 하도록 한정
##---------------------------------------------------------------------------
## Author: YJ
## Logging
##---------------------------------------------------------------------------
log-warnings = 3 # 0 비활성화
# 1 이상: 쿼리문 단위의 경고 내용까지 에러로그에 기록
log_output = FILE,TABLE # 로그 기록 유형 (파일과 테이블에 기록)
log-error = /logs001/mysvc01/MARIASVC/error/mysqld.err # 에러 로그파일 경로
general_log = OFF # 제너럴 로그 비활성화
# DB에서 일어나는 모든 작업에 대한 로그를 남기게 되므로 필요할 때만 ON으로 설정해서 사용
general_log_file = /logs001/mysvc01/MARIASVC/general/mysvc01-general.log # 제너럴 로그파일 경로
slow_query_log = ON # 느린 쿼리 기록 활성화
long_query_time = 0.5 # 느린 쿼리의 기준 시간(초)
log-slow-verbosity = 'query_plan,innodb'
log_queries_not_using_indexes = OFF # 인덱스를 사용하지 않은 쿼리 기록 여부
slow_query_log_file = /logs001/mysvc01/MARIASVC/slow/mysvc01-slow.log # 느린 쿼리 로그파일 경로
##---------------------------------------------------------------------------
## Author: YJ
## DB 기본 설정
##---------------------------------------------------------------------------
skip-name-resolve # 역DNS 검색 비활성화 (IP 기반으로 접속을 하게 되면 hostname lookup 과정 생략)
default_storage_engine='InnoDB' # 기본 스토리지 엔진 설정
lower_case_table_names = 1 # 테이블명을 소문자로 처리
sysdate-is-now # SYSDATE 구문을 NOW와 동일하게 처리
sql_mode="TRADITIONAL,IGNORE_SPACE,ONLY_FULL_GROUP_BY,ANSI_QUOTES"
# sql_mode 설명 : SQL문 사용 제한 = 쿼리 점검 수준
# TRADITIONAL = STRICT_TRANS_TABLES,STRICT_ALL_TABLES = 잘못된 값이 컬럼에 입력되거나 업데이트될 때 에러를 반환함
# ,NO_ZERO_IN_DATE,NO_ZERO_DATE = 날짜타입에 0000-00-00 입력 못 하게 함
# ,ERROR_FOR_DIVISION_BY_ZERO = 0으로 나눌 때는 오류 발생시킴
# ,NO_AUTO_CREATE_USER = 권한 부여 문장이 실행된다고 해서 자동으로 유저를 생성하지 않게 함
# ,NO_ENGINE_SUBSTITUTION = 기본 스토리지 엔진의 자동 대체를 방지
# IGNORE_SPACE : 프로시저나 함수명과 괄호 사이의 공백 무시
# ONLY_FULL_GROUP_BY : 그룹핑 작업을 할 때 GROUP BY 절에 그룹핑 키 컬럼들이 다 있어야만 함
# ANSI_QUOTES : 홑따옴표만 문자열 값 표시로 사용, 쌍따옴표는 문자열 리터를 표기에 사용할 수 없음
# PAD_CHAR_TO_FULL_LENGTH : MariaDB/MySQL은 기본적으로 CHAR 타입도 VARCHAR 처럼 문자열 뒤 공백 문자를 제거하는데, 공백을 제거하지 않고 채우게 하려면 설정함
#feedback = ON # MariaDB로 에러 내용 보내기
event_scheduler = ON # 이벤트스케줄러(cron, Oracle의 Job과 같은 역할) 활성화
performance_schema = ON # performance_schema 활성화
#performance_schema_max_digest_length=10240 # digest의 최대 길이 (digest:정형화시킨 쿼리문, 상수부분 등을 패턴화시킨다.)
plugin-load = server_audit
##---------------------------------------------------------------------------
## Author: YJ
## Character Set
##---------------------------------------------------------------------------
skip-character-set-client-handshake # 클라이언트에서 보내지는 문자셋 정보를 무시하고 서버의 문자셋 사용
character_set_server = utf8mb4
collation_server = utf8mb4_bin
init_connect='SET collation_connection = utf8mb4_bin'
init_connect='SET NAMES utf8mb4'
##---------------------------------------------------------------------------
## Author: YJ
## Transaction 설정
##---------------------------------------------------------------------------
autocommit = ON # autocommit 활성화 여부
transaction_isolation = "READ-COMMITTED" # replication을 할 때는 "레코드 기반 복제"를 사용하도록 함
# transaction_isolation 설명
# . READ UNCOMMITTED
# 다른 트랜잭션이 Commit 전 상태를 볼 수 있음
# Binary Log가 자동으로 Row Based로 기록됨 (Statement설정 불가, Mixed 설정 시 자동 변환)
# . READ-COMMITTED
# Commit된 내역을 읽을 수 있는 상태로, 트랜잭션이 다르더라도 특정 타 트랜잭션이 Commit을 수행하면 해당 데이터를 Read할 수 있음
# Binary Log가 자동으로 Row Based로 기록됨 (Statement설정 불가, Mixed 설정 시 자동 변환)
# . REPEATABLE READ (기본)
# MySQL InnoDB 스토리지 엔진의 Default Isolation Level
# Select 시 현재 데이터 버전의 Snapshot을 만들고, 그 Snapshot으로부터 데이터를 조회
# 데이터에 관해서 암묵적으로 Lock과 비슷한 효과가 나타남. 즉, Select 작업이 종료될 때까지 해당 데이터 변경 작업 불가
# 동일 트랜잭션 내에서 데이터 일관성을 보장하고 데이터를 다시 읽기 위해서는 트랜잭션을 다시 시작해야 함
# . SERIALIZABLE
# 가장 높은 Isolation Level로 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸림
# 다른 트랜잭션에서는 해당 영역에 관한 데이터 변경 뿐만 아니라 입력도 불가
##---------------------------------------------------------------------------
## Author: YJ
## 보안 설정
##---------------------------------------------------------------------------
#skip-external-locking # 외부(TCP/IP) 잠금 비활성화
enable-secure-auth # 서버로 구버전(4.1버전 이하) 포멧으로 된 패스워드 전달 비활성화
symbolic-links = OFF # 심볼릭 링크 비활성화
##---------------------------------------------------------------------------
## Author: YJ
## Connection 설정
##---------------------------------------------------------------------------
thread_handling = one-thread-per-connection # 쓰레드풀(Thread Pool) 사용 여부
# 쓰레드풀을 사용하려면 pool-of-threads 으로 설정
max_connections = 250 # 허용 가능한 최대 동시 접속수, 각각의 커넥션은 최소 thread_stack의 사이즈만큼의 메모리 사용
max_connect_errors = 1000 # 계속적으로 문제를 발생시키는 클라이언트를 몇번째 재시도후 block할지 지정
# 한번 block되면, 서버를 재시작하거나 flush host명령을 실행하기 전까지 접속 불가
back_log = 100 # max_connections 이상의 connection이 대량으로 몰릴 때 큐에 대기가능한 커넥션의 갯수
thread_cache_size = 100 # 재 사용을 위해 보관할 쓰래드 수, thread_created가 높을 경우 증가됨
# THREADS_CONNECTED 상태값의 피크보다 약간 낮게 설정하는 것을 권장함
wait_timeout = 28800 # 접속한 후 쿼리가 들어올 떄까지 대기하는 시간(초) = noninteractive 커넥션 닫기까지의 시간
lock_wait_timeout = 28800 # metadata lock을 획득하기 위해 대기하는 시간(초), 기본은 1년임
interactive_timeout = 3600 # "mysql>"과 같은 콘솔이나 터미널 상에서 클라이언트의 접속을 시간(초), 기본 8시간이지만 1시간 설정 권장
connect_timeout = 10 # mysqld 데몬이 클라이언트로 부터 접속요청을 받는 경우 기다리는 시간(초)
#net_retry_count = 10 # 통신이 잘못되어 실패할 때, 몇 번까지 재시도할지
net_read_timeout = 60 # 커넥션으로부터 읽기가 안 된다고 판단하기 전에 데이터를 기다리는 시간(초)
net_write_timeout = 60 # 커넥션으로 쓰기가 안 된다고 판단하기 전에 기다리는 시간(초)
open_files_limit = 3000 # mysql이 오픈할수 있는 file(정확히는 file descripter)개수
# 가능하면 5000으로 설정하는데 OS limit에 따라 재조정 될수 있다
# 실제로는 이 값에 영향을 받지 않고, OS의 nofile(open files) 제한이 적용됨
table_open_cache = 4000 # DB전체에서 오픈할 수 있는 테이블 갯수
table-definition-cache = 4000 # 캐싱해 놓을 (.frm 파일에서 추출한)테이블 정의 갯수, 테이블이 많으면 크게 설정
##---------------------------------------------------------------------------
## Author: YJ
## Thread Pool 설정 - thread_handling = pool-of-threads 일 때만 의미 있음
##---------------------------------------------------------------------------
# thread_pool_size = 4 # 쓰레드 그룹 갯수, 기본은 CPU 갯수와 같음
# (sleep이나 wait 상태인 쓰레드 제외하고) CPU를 동시에 사용할 수 있는 쓰레드 갯수
# 리눅스나 유닉스 계열일 때만 사용되는 설정
# thread_pool_max_threads = 500 # 쓰레드풀에 들어갈 수 있는 최대 쓰레드 갯수
# thread_pool_idle_timeout = 60 # idle 상태인 쓰레드를 정리하기 전에 대기하는 시간(초)
# thread_pool_stall_limit = 500 # 쓰레드 교착 상태 검사 간격(밀리초)
# 쓰레드 갯수가 thread_pool_max_threads에 도달하면 쓰레드는 더 이상 생성되지 않는다.
# thread_pool_oversubscribe = 3 # internal 파라미터로 임의로 수정하지 않는 것이 좋음
# thread_pool_size * thread_pool_oversubscribe = DB에서 동시에 active되어 CPU를 사용할 수 있는 쓰레드 갯수
##---------------------------------------------------------------------------
## Author: YJ
## Connection 메모리 설정
##---------------------------------------------------------------------------
sort_buffer_size = 256K # (인덱스를 사용할 수 없는) 정렬에 필요한 버퍼의 크기, ORDER BY 또는 GROUP BY 연산 속도와 관련
join_buffer_size = 256K # 조인이 테이블을 풀스캔 하기 위해 사용하는 버퍼크기, 드리븐 테이블이 FULL SCAN할 때 사용됨
read_buffer_size = 256K # 테이블 스캔에 필요한 버퍼크기
read_rnd_buffer_size = 256K # 디스크 검색을 피하기위한 랜덤 읽기 버퍼크기, 정렬 대상이 커서 two pass 알고리즘을 쓸 때만 사용
#thread_stack = 256K # 쓰레드 하나의 스택 사이즈 (기본 64bit 시스템의 기본 256KB)
net_buffer_length = 16K # 클라이언트에 보내는 초기 메시지의 바이트 수
max_allowed_packet = 16M # 한 패킷의 최대 크기
group_concat_max_len = 32M # GROUP_CONCAT() 함수를 사용할 때 이용할 수 있는 최대 크기
max_heap_table_size = 32M # MEMORY 테이블의 최대 크기
tmp_table_size = 1M # 메모리에 생성될 임시 테이블의 최대 크기, 이 값을 초과하면 디스크에 임시 테이블을 씀
##---------------------------------------------------------------------------
## Author: YJ
## 쿼리 캐시 설정
##---------------------------------------------------------------------------
query_cache_size = 32M # 쿼리 결과를 캐싱하기 위해 할당하는 메모리 크기 (DB전체)
query_cache_limit = 2M # 쿼리 결과가 이 값보다 크면 캐싱 안 함 (기본은 1M)
query_cache_type = DEMAND # 쿼리에서 힌트로 쿼리 캐시를 사용하겠다고 설정한 경우에만 쿼리 캐시 사용
# 0 or OFF : 쿼리 캐시 사용 안 함, 쿼리 캐시를 안 쓰려면 query_cache_size도 0으로 설정해야 함
# 1 or ON : SQL_NO_CACHE를 설정하지 않은 모든 쿼리의 결과를 캐싱함
# 2 or DEMAND : SQL_CACHE로 설정한 쿼리의 결과만 캐싱함
##---------------------------------------------------------------------------
# Author: YJ
# MariaDB 에서 사용할 수 있는 최대 메모리 사이즈
# innodb_buffer_pool_size + innodb_additional_mem_pool_size + innodb_log_buffer_size + key_buffer_size + query_cache_size
# + max_connections * ( read_buffer_size + read_rnd_buffer_size + sort_buffer_size + join_buffer_size + thread_stack + binlog_cache_size)
##---------------------------------------------------------------------------
##---------------------------------------------------------------------------
## Author: YJ
## InnoDB 설정
##---------------------------------------------------------------------------
#innodb_page_size = 16K
#innodb_use_sys_malloc = ON # OS에서 제공되는 메모리 할당기능 사용 여부, ON: InnoDB에서 OS 자원을 사용
# InnoDB의 메모리 할당기능과 OS에서 제공되는 메모리 할당 기능 중 더 효율이 높은 쪽을 선택할 수 있음
innodb_buffer_pool_size = 512M # InnoDB 엔진으로 된 테이블과 인덱스를 캐시하기 위한 메모리 버퍼 크기
# 초기 시스템 전체 물리 메모리의 40% 수준으로 설정하고 사용량에 따라 증감
innodb_buffer_pool_instances = 2 # 버퍼풀의 갯수, 적절한 갯수로 나누면 뮤텍스(mutex) 경합이 줄어들어 DB 동시 처리 성능을 높여줌
# 각각의 버퍼풀은 각각의 플러쉬 리스트 뮤텍스(mutex)를 가짐 (아마 LRU리스트도 가질 듯)
# 각 버퍼풀은 InnoDB 엔진이 자동으로 적절히 배분해서 사용함
#innodb_additional_mem_pool_size = 16M # DEPRECATED됨, 데이터 디렉토리 정보와 내부 데이타 구조를 저장하는 메모리 풀의 크기
innodb_data_file_path=ibdata1:32M;ibdata2:32M:autoextend # 시스템테이블스페이스 - 파일명:초기크기:자동증가:최대크기
innodb_file_per_table = 1 # 테이블 단위로 테이블스페이스 할당, 활성시 테이블별로 .frm, .ibd 각각 생성
innodb_data_home_dir = /data001/mysvc01/MARIASVC # 테이블 생성 기본 경로
#innodb_autoextend_increment = 100 # 테이블스페이스 자동 확정시 크기
innodb_log_buffer_size = 4M # 로그(redo) 버퍼 크기
# 클수록 디스크 사용량이 줄어서 성능이 향상되지만 시스템 다운시 손실되는 트랜잭션 양도 증가됨
# 크기가 작으면 로그버퍼를 로그파일로 쓰기 위한 부하가 많이 발생할 수도 있음
innodb_log_group_home_dir = /data001/mysvc01/MARIASVC # 로그(redo) 경로
innodb_log_files_in_group = 3 # 로그(redo) 파일 갯수
innodb_log_file_size = 64M # 로그(redo) 파일 크기
# 일반적으로 (innodb_buffer_pool_size/innodb_log_files_in_group)를 적정 값으로 본다.
innodb-support-xa = OFF # 트렌젝션 two-phase commit 지원, 디스크 플러시 횟수를 줄여 성능항상
# 분산데이터 기능 (2-PhaseCommit)
innodb_buffer_pool_dump_at_shutdown = 1 # DB shutdown할 때 innodb_log_buffer에 있던 내용을 dump 파일로 내림
innodb_buffer_pool_filename = innodb_buffer_pool_dump # DB shutdown할 때 innodb_log_buffer에 있던 내용을 담을 dump 파일명
innodb_buffer_pool_load_at_startup = 1 # DB startup할 때 dump파일로 받아 놨던 내용을 innodb_log_buffer에 올림
innodb_thread_concurrency = 4 # InnoDB가 동시 사용가능한 최대 시스템 쓰래드 수
# CPU의 2~4배 권장, 0으로 설정하면 동시성이 비활성화 됨
#innodb_thread_sleep_delay=0 # InnoDB queue에 들어가기전에 얼마나 sleep할것인가
# innodb_thread_concurency에 도달하면 새로운 쓰레드는 innodb_thread_sleep_delay 동안 Sleep 함
# innodb_thread_concurency = 0 이면 이 값음 무시됨
#innodb_adaptive_max_sleep_delay = 150000 # 0 이상의 값으로 지정하면, InnoDB가 innodb_thread_sleep_delay를 자동으로 조정
#innodb_concurrency_tickets = 500 # 한번 스케줄링된 쓰레드는 설정된 티켓개수만큼 자유롭게 InnoDB를 사용할수 있다
# 여러 쓰레드가 innodb_thread_concurrency에 도달하면 하나의 쓰레드만 큐에 들어갈 수 있음
# 하나의 쓰레드가 InnoDB에 들어가게 되면, innodb_concurrency_tickets의 값과 일치하는 “자유 티켓”의 숫자가 주어지고,
# 쓰레드가 자신의 티켓을 사용하기 전 까지는 자유롭게 InnoDB에 들어가고 나올 수가 있다.
# 이런 후에는, 쓰레드는 다시금 일관성 검사를 하고 InnoDB에 다시 들어가려고 시도하게 된다
# InnoDB는 IO request를 background threads에 가능한한 동등하게 분배하고, 동일한 extent에 대한 read requests는 동일한 thread에게 할당함
innodb_read_io_threads = 4 # InnoDB 읽기 작업을 위한 I/O 쓰레드의 수, 주목적: read-ahead requests
# SHOW ENGINE INNODB STATUS 에서 pending read requests가 64 x innodb_read_io_threads이상이라면,
# innodb_read_io_threads를 더 할당하는 것을 고려
innodb_write_io_threads = 4 # InnoDB 쓰기 작업을 위한 I/O 쓰레드의 수
# read-ahead 란?
# 하나의 extent(64개 pages group)을 모두 buffer pool에 prefetch하는 작업. (asynchronous request임)
# 이들 페이지도 곧 읽혀질거라는 가정하에 모두 버퍼에 올리는 것
# 알고리즘)
# linear read-ahead technique: 버퍼풀 안에 순차적으로 읽혀진 페이지 개수로 판단
# 만약 하나의 extent내에서 순차적으로 읽혀진 페이지 개수가 innodb_read_ahead_threshold 이상이면 다음 extent전체 페이지를 read-ahead
# random read-ahead technique: 버퍼풀 안에 존재하는 페이지 개수로 판단(순차적인지 여부와 무관함)
# 만약 한 extent내의 13개의 연속된 페이지가 버퍼풀에 존재한다면, 해당 extent의 나머지 pages들을 read-ahead한다
innodb_lock_wait_timeout = 1200 # 트랜잭션 락(record lock)을 대기하는 시간(초)
#innodb_flush_neighbors = 1 # InnoDB 버퍼풀에서 페이지 플러시를 할 때(=디스크로 기록할 때), 인접한 더티 페이지도 (단일 I/O로) 플러시할 지 결정하는 변수
# 랜덤액세스 쓰기 성능이 떨어지는 HDD에서는 좋으나, SSD에서는 비활성화하는 것이 성능에 유리함
# 0: 해제, 1: 같은 extent안에 연속된 더티 페이지를 같이 플러시함, 2: 같은 extent안에 모든 더티 페이지를 플러시함
#innodb_io_capacity = 100 # 백그라운드 플러싱 속도 제어를 위한 변수, 큰 값을 지정하면 I/O 대역폭을 점유하므로 환경에 맞춰서 설정할 것
# InnoDB 메인 쓰레드가 I/O 작업을 할 수 있는 capa, 시스템의 I/O 수준에 의존적임
# 일반적으로 7200 RPMs 하드 드라이브인 경우 100으로 설정
# RAID 구성이나 SSD 사용 등에 따라서 더 높은 값으로 설정
# Raid1: 200. Raid10: 200 x write arrays. SSD: 5000. FusionIO: 20000
innodb_flush_log_at_trx_commit = 0 # InnoDB에서 커밋될 때마다 로그(redo)를 디스크에 플러시할지를 결정하는 옵션
# fsync() 함수를 호출하는 빈도에 관한 옵션
# 0 : 커밋될 때마다 디스크 플러시를 하지는 않음, OS에서 적절한 시점(일반적으로 4~5초 간격)마다 데이터 동기화를 처리하게 됨
# 잘 못 되면 4~5초간의 데이터는 유실될 수도 있음
# 1 : 트랜잭션이 커밋될 때마다 로그 파일에 기록되고 디스크 플러시가 실행 (가장 안전, 가장 느림)
# 2 : 커밋되면 강제로 로그 버퍼를 로그 파일에 쓰지만, 1초가 지나기 전에는 디스크에 저장되지 않음
innodb_flush_method = O_DIRECT
# InnoDB가 dafa files, log files로 data를 flush(디스크에 기록하고 동기화하는 작업)하는 방법
# ------------------+----------+----------+-----------+-----------------+-----
# Method | log file | log file | data file | data file flush | 설명
# Method | open | fulsh | open | data file flush | 설명
# ------------------+----------+----------+-----------+-----------------+-----
# fsync | normal | fsync() | normal | fsync() | 기본
# O_DSYNC | O_SYNC | O_SYNC | normal | fsync() | synchronized(동기) I/O로서, write작업시 hardware단까지 fsync함
# O_DIRECT | normal | fsync() | O_DIRECT | fsync() | OS caching을 하지 않고 direct I/O로 innodb_buffer_pool에서 file로 I/O함
# O_DIRECT_NO_FSYNC | normal | fsync() | O_DIRECT | skip fsync() | O_DIRECT와 동일한데 data file 동기화를 위한 fsync 호출을 생략함
# ------------------+----------+----------+-----------+-----------------+-----
# fsync = 데이터와 메타정보를 함께 변경하는 방식 (파일메타정보는 파일변경일시,수정자 등을 의미함, fdatasync "데이터만 변경, 메타데이터는 무시")
# O_DIRECT = pache cache, buffer cache는 directly하게 write bypass하지만, inode cache, directory cache, metadata는 따로 fsync()를 호출해서 flush 해줘야 함
# (캐시메모리 장착된)RAID 컨트롤러가 없거나 SAN을 사용할 때는 O_DIRECT를 사용 하지 않는 것이 좋음
# double buffering(InnoDB buffer pool과 OS file system cache에 두번 캐쉬)을 하지 않기 떄문에 성능향상을 기대할 수 있다.
# O_DIRECT_NO_FSYNC = 몇몇 file system에서는 O_DIRECT가 fsync()없이도 metadata까지 synchronize되는 걸 보장함. 그래서 InnoDB가 O_DIRECT_NO_FSYNC를 추가함
# 디스크에 데이터를 쓰는 방법 = 1단계 "운영체로의 버퍼로 기록" + 2단계 "버퍼의 내용을 디스크로 복사"
# - 동기(Sync) I/O = 1단계와 2단계를 함께 실행
# - 비동기(Async) I/O = 1단계와 2단계를 다른 시점에 실행
# - direct I/O = 1단계 무시, 2단계 "버퍼의 내용을 디스크로 복사"만 실행
innodb_adaptive_hash_index = ON
# Adaptive Hase Index
# 1. workload와 충분한 buffer pool memory의 적절한 조합하에서, 트랜잭션 특성이나 신뢰성에 위배되지 않는 선에서, InnoDB를 in-memory DB처럼 동작하게 함
# 2. 동작
# 1) MySQL은 search 패턴을 고려하여 index prefix(인덱스 키의 값 앞부분)로 hash index를 만든다
# 2) 자주 access되는 인덱스 페이지에 대해서만 부분적으로 생성될 수도 있다.
# 3) InnoDB는 index search 패턴을 모니터링하는 메커니즘을 가지고 있어서 해당 쿼리가 hash index를 사용하면 이익이라고 판단되면, 자동으로 hash index를 생성한다
# 4) 만약 테이블 전체가 메모리에 들어갈수 있는 사이즈인 경우, hash index는 쿼리 속도를 향상시킨다.
# 인덱스를 pointer와 같이 동작하게 해서 원하는 로우를 바로 다이렉트하게 찾을수 있다.
# 5) 자주 사용되는 데이터는 해시를 통해서 직접 접근할 수 있기에, Mutex Lock으로 인한 지연은 확연하게 줄어듦
# 6) heavy workload하에서는(동시 대량 배치 작업 등), adaptive has index를 접근할때 획득하는 read/write lock이 contention의 원인이 되기도 한다
# 7) LIKE % 쿼리의 경우에는 Adaptive Hase Index가 별 이득이 안 된다
# 3. 모니터링
# 1) 할당되는 메모리는 Innodb_Buffer_Pool_Size의 1/64만큼으로 초기화(최소가 그렇고 최대는 알 수 없음)
# 지나치게 커지지 않도록 상태의 주기적 확인 필요 (SHOW GLOBAL STATUS LIKE 'Innodb%adaptive%';)
# 2) SHOW ENGINE INNODB STATUS 에서 SEMAPHORE 섹션에 RW-latch를 대기하는 thread가 여러개 있다면, disable하는 것이 더 좋을 수도 있다.
# 3) 테이블 DROP은 최대한 트래픽이 없는 새벽에, Adaptive Hash Index를 순간 OFF/ON을 하여 메모리를 해제하고, 테이블을 DROP하는 것이 좋다.
innodb_adaptive_hash_index_partitions = 2
# adaptive_hash_index를 몇 개로 나눠쓸지 결정하는 변수
# 기본은 1 이며, 1일 때는 단일 Mutex로 관리되기 때문에 테이블을 DROP하게 되면 adaptive_hash_index에서 관련 정보를 정리하려고 하면서
# adaptive_hash_index 덕을 보던 쿼리들까지 영향을 받을 수 있음
# 변수값을 크게 설정하면 Mutex가 여러 개가 되면서 테이블을 DROP할 때 adaptive_hash_index에서 Mutex 경합으로 인해 발생할 수 있는 문제를 줄일 수 있음
# InnoDB 내부적으로는 테이블 DROP시 Sleep없이 죽으라고 Hash Index에서 관련 노드를 모두 삭제한 후 테이블이 제거
# 개인적인 생각으로는 CPU 개수 정도면 적당할 듯 함
#innodb_change_buffering = all # change buffering 설정
# change buffering = insert buffering + delete buffering + purge buffering
# all : 기본: buffer inserts, delete-marking operations, and purges.
# none : Do not buffer any operations.
# inserts : Buffer insert operations.
# deletes : Buffer delete-marking operations.
# changes : Buffer both inserts and delete-marking.
# purges : Buffer the physical deletion operations that happen in the background.
# Innodb는 인덱스 leaf node를 업데이트하지 않고 buffer만 해둠, 버퍼에 임시로 저장해 두고 나중에 여유가 될 때 실제 인덱스에 병합함
# secondary index의 leaf node를 update하려면, 디스크로부터 index page를 읽어서 변경해야하는데 이는 부수적으로 추가 IO가 필요한 작업이기 때문
# 저장: change buffer는 system tablespace에 위치함
# 조건: non-unique한 인덱스에 대한 변경사항 저장, 변경작업에 해당하는 page가 buffer pool에 존재하지 않을때만 change buffer에 변경을 저장
# merge 작업)
# background thread에 의한 주기적으로 병합
# 해당 page가 다른 read operation에 의해서 buffer pool로 불려읽혀졌을 때
#innodb_change_buffer_max_size=25 # 버퍼풀에서 change_buffer가 차지할 비율
#innodb_old_blocks_pct = 37 # LRU 리스트 영역의 범위(퍼센트)
#innodb_old_blocks_time = 1000 # LRU 리스트에서 MRU 리스트로 옮기기 전에 대기하는 시간(밀리초)
# MRU: Most Recently used list, LRU: Last Recently used list
# 버퍼풀의 페이지를 관리하는 리스트 = MRU 리스트 + LRU 리스트
innodb_autoinc_lock_mode = 1
# auto_increment 칼럼에 들어갈 값을 위한 lock 설정
# 0 : insert 할 때 마다 auto increment lock 사용, insert ... select ... 처럼 대량 데이터 입력할 때는 lock 대기가 길어짐
# 1 : insert ... select ... 처럼 대량 데이터 입력할 때 미리 일정량의 자동 증가값을 만들어 사용
# 미리 만든 일정량의 자동 증가값이 다 사용되지 않으면 나머지는 버림
# 2: auto increment lock을 사용하지 않고 mutex 사용, auto_increment 값이 유니크함은 보장하지만 순서는 보장하지 못 함
#innodb_max_dirty_pages_pct=75 # 버퍼풀에 남아 있을 수 있는 더티 페이지의 비율 (이 비율이 넘어가면 체크포인트가 수행됨)
# 더티페이지(dirty page) = SQL 조작으로 변경됐지만 아직 디스크에 쓰여지지 않은 데이터 페이지
#innodb_adaptive_flushing=ON # InnoDB 엔진이 리두 로그의 발생량을 모니터링 하면서 버퍼 풀의 더티페이지를 디스크로 쓰는 작업 속도를 조절하게 함
# ON 이 아니면 더티페이지의 비율이 innodb_max_dirty_pages_pct를 넘어서는 순간 공격적인 디스크 쓰기 일어날 수 있음
#innodb_use_native_aio=ON # 리눅스와 윈도우 플랫폼에 한해 네이티브 비동기 I/O 방식이 제공됨 (I/O요청 동시성 증대 효과)
# libaio 라이브러리가 설치되어 있고, 이 값을 "ON"으로 설정해야 사용 가능함
innodb_doublewrite = 1 # doublewrite buffer와 data file에 이중 쓰기 활성화 (기본: 활성)
# 목적: 시스템 crash, 전원공급중단 등 장애시 보다 안전한 리커버리
# OS의 기본IO 단위(보통 4K)와 DB의 기본IO단위(보통 16K)가 다름으로 인해 발생할 수 있는 page currupt를 방지하기 위해 사용
# (16K가 OS를 통해 다 써지기 전에 시스템 crash가 가 되도, 안전하게 복구할 수 있도록 도와줌)
# InnoDB는 full pages를 로깅하지는 않으므로 필요함
# InnoDB는 log file에 page number, 변경내용, log sequence 정보를 기록함
# Doublewrite Buffer 는?
# 1. 기본적으로 system tablespace에 위치함
# 2. Flush 이벤트 발생시 Doublewrite Buffer를 먼저 쓰고, 그 다음에 대상 페이지의 내용을 변경함
# (대상 페이지의 변경 작업은 fsync()를 call해서 진행됨)
# 3. Doublewrite Buffer에 기록되는 내용은 해당 페이지 정보와 operation 정보임
# 4. 여러 개의 dirty page를 각각의 데이터파일에 플러쉬하려면 랜덤I/O가 발생하여 시간이 오래 걸리므로
# dirty page를 모아서 시스템 테이블스페이스 내 하나의 연속적인 extent에 쓰고 단일 I/O로 처리
# 5. fsync() 횟수 줄임 - 매 page마다 fsync()를 콜하는게 아니라, multiple page를 한번에 쓰고 fsync()
# 6. 일반적으로 doublewrite를 활성화에 의해서 발생하는 성능 저하는 5% 정도로 본다.
#innodb_sync_spin_loops = 30 # 쓰레드가 지연되기 전에 (suspended) 풀어 주기 위해 InnoDB 뮤텍스(mutex)를 기다리는 쓰레드의 대기 시간
# spin loop: CPU를 사용하면서 락이 해제됐는지 검사하는 것
# 동일한 쿼리가 동시다발적으로 유입되어 여러 스레드에서 메모리내의 같은 데이터 블록에 접근하여 뮤텍스 경합이 발생,
# CPU 부하가 높아지는 경우에는 이 값을 줄여가면 부하가 줄어들 수도 있음 (10정도까지는 괞찮을 듯)
#innodb_table_locks = 1 # LOCK TABLES은 AUTOCOMMIT=0경우에, InnoDB로 하여금 내부적으로 테이블을 잠금
#innodb_max_purge_lag = 0 # 퍼지 연산 (purge operation)이 래깅(lagging)될 때 INSERT, UPDATE 및 DELETE 연산을 지연 시키는 방법을 제어
# 디폴트값 0일시 지연 없음
#innodb_commit_concurrency = 0 # 동시에 commit 처리를 할 수 있는 쓰레드의 숫자. 값이 0이 되면 동시성 제어(concurrency control)가 비활성화
#innodb_purge_threads = 1 # purge 작업을 실행할 쓰레드의 수 (기본1~최대32)
# InnoDB의 purge 작업
# 예전) 주기적으로 수행되는 가비지 컬렉션 작업의 한 종류, 마스터 쓰레드에 의해 동작됨, purge하는 동안 다른 데이터베이스 작업들은 대기해야 함
# MySQL 5.5이후) 개별의 쓰레드에서 수행되면서 더 높은 동시성 보장
innodb_file_format = barracuda # InnoDB 파일 포멧: 테이블압축 등의 기능을 사용하려면 barracuda 사용
innodb_file_format_max = barracuda
innodb_large_prefix = ON # 인덱스 키 칼럼의 prefix를 767 bytes 이상으로 설정 (최대 3072 bytes까지 설정 가능)
innodb_open_files = 4000 # DB전체에서 동시에 열어 놓을 수 있는 InnoDB 테이블의 .ibd 파일의 수
#innodb_stats_persistent = 1 (ON) # 통계정보를 주기적으로 mysql.innodb_table_stats, mysql.innodb_index_stats 테이블에 영구히 저장
#innodb_stats_auto_recalc = 1 (ON) # 주기적으로 통계 정보를 갱신
#innodb_stats_persistent_sample_pages = 20 # mysql.innodb_table_stats, mysql.innodb_index_stats 테이블에 영구히 저장할 통계정보 수집에 사용할 샘플 페이지 수
#innodb_stats_sample_pages = 8 # 통계정보 수집에 사용할 샘플 페이지 수
#innodb_stats_on_metadata = OFF # 다음 명령들이 실행될 때 통계 정보 갱신 활성화
# SHOW TABLE STATUS, SHOW INDEX, INFORMATION_SCHEMA.TABLES 조회, INFORMATION_SCHEMA.STATISTICS 조회
innodb_show_verbose_locks = 1 # "SHOW ENGINE INNODB STATUS"에 락이 잡힌 레코드 표시
innodb_print_all_deadlocks = ON # 에러 로그에 InnoDB 데드락 정보 기록 활성화
#innodb_status_output = ON; # 에러 로그에 "SHOW ENGINE INNODB STATUS" 결과 포함 설정
innodb_status_output_locks = ON # InnoDB Status를 보는 부분("SHOW ENGINE INNODB STATUS" 혹은 에러로그)에 lock 정보도 함께 표시되도록 함
#innodb_force_recovery = 0
# 크래시 복구 모드 설명 : 큰 값은 작은 값의 내용을 포함함
# 1 (SRV_FORCE_IGNORE_CORRUPT) 서버가 깨진 페이지를 발견한다고 하더라도 계속 구동하도록 만듦
# 2 (SRV_FORCE_NO_BACKGROUND) 메인 쓰레드가 구동되지 못 하도록 함
# 3 (SRV_FORCE_NO_TRX_UNDO) 복구 다음에 트랜젝션 롤백을 실행하지 않음
# 4 (SRV_FORCE_NO_IBUF_MERGE) 삽입 버퍼 병합 연산 (insert buffer merge operations)까지 금지
# 5 (SRV_FORCE_NO_UNDO_LOG_SCAN) 데이터베이스를 시작할 때 UNDO log를 검사하지 않음
# 6 (SRV_FORCE_NO_LOG_REDO) 복구 연결에서 로그 롤-포워드 (roll-forward)를 실행하지 않음
##---------------------------------------------------------------------------
## Author: YJ
## MyISAM 스토리지 엔진 관련 설정
## InnoDB를 사용하지 않고 MyISAM만 사용한다면 key_buffer_size를 크게 설정
##---------------------------------------------------------------------------
key_buffer_size = 16M # MyISAM 테이블이 거의 없고, 데이터도 매우 적으므로 아주 작게 설정
bulk_insert_buffer_size = 1M
myisam-recover-options = BACKUP,FORCE # MyISAM 테이블을 열 때 자동 복구 옵션
myisam_sort_buffer_size = 1M # 인덱스 정렬시 할당되는 버퍼의 크기
myisam_max_sort_file_size = 64M # 인덱스 재 생성시 사용할 임시 파일의 최대 크기
#myisam_repair_threads = 1 # 정렬 복구시 사용될 쓰레드 갯수
#ft_min_word_len # MyISAM 혹은 InnoDB 테이블 FULLTEXT 인덱스를 만들 때 포함될 단어의 최소 길이 (mgroonga와는 관련 없는 설정)
# 이 값을 변경하면 "REPAIR TABLE 테이블이름 QUICK" 으로 재 구축해야함
##---------------------------------------------------------------------------
## Author: YJ
## Aria 스토리지 엔진 관련 설정
## internal temporary table이 생성될 때는 기본적으로 Aria 스토리지 엔진을 사용하므로 지나치게 작게 설정하지 말 것
## 예: aria_pagecache_buffer_size = 1M
##---------------------------------------------------------------------------
aria_pagecache_buffer_size = 32M
aria_sort_buffer_size = 32K
aria_log_file_size = 64M
##---------------------------------------------------------------------------
## Author: YJ
## 통계 및 Optimizing 관련 설정
##---------------------------------------------------------------------------
use_stat_tables = NEVER # 스토리지 엔진 통계 정보와 통합 통계 정보를 이용하는 우선순위를 결정
# NEVER: 스토리지 엔진 통계정보만 수집
# COMPLEMENTARY : 스토리지 엔진 통계정보를 우선 사용하고 정보가 부족하면 통합 통계 정보 사용
# PREFERABLY: 통합 통계정보를 우선 사용 사용하고 정보가 없으면 스토리지 엔진 통계 정보 사용
# 통합 통계정보란? mysql.table_stat, mysql.column_stat, mysql.index_stat
histogram_size = 20 # 히스토그램을 저장할 공간 크기(bytes단위), 히스토그램 정보는 mysql.column_stat 저장
# 0 ~ 255 까지 설정 가능, 0이면 히스토그램 수집 안 함
# MariaDB는 Height-Balanced Histogram 알고리즘 사용, 버킷에 저장된 최대값을 1byte 할당해서 저장
histogram_type = SINGLE_PREC_HB #
# SINGLE_PREC_HB : histogram_size 만큼 버킷 생성
# DOUBLE_PREC_HB : histogram_size/2 만큼 버킷 생성 (버킷당 2byte를 사용하는 대신 정확성을 확대했기 때문)
#optimizer_prune_level = 1 # 조인 순서 결정 알고리즘 선택 (1: Greedy 방식, 2: Exhaustive 방식)
optimizer_search_depth = 20 # Greedy 방식에서 쿼리에 있는 테이블 중 몇개 테이블의 조인 순서 최적화를 찾을 지 결정 (기본 62)
optimizer_use_condition_selectivity = 4 # 옵티마이저 선택도(1~5)
# 1: MariaDB 5.5 버전에서 사용하던 선택도 예측 방식을 유지(디폴트 값)
# 2: 인덱스가 생성된 칼럼의 조건에 대해서만 선택도 판단
# 3: 모든 칼럼의 조건에 대해서 선택도 판단(히스토그램 사용 안함)
# 4: 모든 칼럼의 조건에 대해서 선택도 판단(히스토그램 사용)
# 5: 4에 추가적으로 범위 검색이 아닌 조건에 대해서는 샘플링 정보를 이용해 선택도를 판단
userstat = ON # Enable INFORMATION_SCHEMA.%_STATISTICS tables
##---------------------------------------------------------------------------
## Author: YJ
## Binary Logs
##---------------------------------------------------------------------------
server_id = 1
# Binary Log 설명
# 1. 써지는 시점
# 1) 트랜잭션을 지원하는 스토리지 엔진(예: InnoDB)
# commit 된 후 lock이 해지 되지 않은 상태에서 쿼리를 로깅
# commit 전에는 쿼리 정보가 cache되고 commit 될 때 모든 쿼리 정보가 로깅됨
# 2) 트랜잭션을 지원하는 않는 스토리지 엔진(예: MyISAM)
# 쿼리 실행 직후 바로 로깅됨
# 트랜잭션 안에 트랜잭션을 지원하지 않는 테이블이 섞이면, 트랜잭션이 롤백되도 그 테이블의 데이터는 롤백 안 됨
# 2. 활성화 방법
# log_bin 설정
log_bin = /data001/mysvc01/binary_MARIASVC/mysvc01-bin # binary log 경로
#binlog_cache_size = 256K # 쓰레드 별로 binary logging과 관련된 내용을 저장하기 위한 캐시 사이즈로 트랜잭션 지원 구문만을 위해 사용됨
# 큰 다중문 트랜잭션을 번번히 사용한다면 이 사이즈를 크게 잡아서 퍼포먼스를 개선할 수 있음
# 최대 사이즈: max_binlog_cache_size로 설정가능
#binlog_stmt_cache_size = 32K # 쓰레드 별로 binary logging과 관련된 내용을 저장하기 위한 캐시 사이즈로 트랜잭션 지원하지 않는 구문만을 위해 사용됨
# 최대 사이즈: max_binlog_stmt_cache_size로 설정가능
#binlog_checksum = NONE # NONE: binary log의 이벤트가 제대로 작성됐는지 각각의 이벤트 길이를 체크해서 확인
max_binlog_size = 256M # binary log file 최대 크기
binlog_format = ROW # binary log에 기록할 데이터 유형
# transaction_isolation이 "READ-COMMITTED" 이상이면 "MIXED" 이상으로 설정해야 함
# STATEMENT: 명령문 기록
# MIXED : 몇몇 일관성을 보장하지 못 하는 경우에는 ROW 포멧으로, 그 외에는 STATEMENT 포멧으로 기록
# ROW: 실제 레코드 기록
sync_binlog = 0 # DB의 binary log 동기화 빈도 설정
# 0: binary log를 기록하지만 직접적으로 플러시(동기화)를 실행하지 않고, OS에 맡김 (리눅스 계열은 3~5초 간격으로 자동 플러시함)
# 1: binary log의 쓰기가 발생할 때마다 디스크 동기화 수행
# binary log 손실은 없지만 잦은 디스크 I/O로 느려질 수 있음
# 1 이상의 값: 설정된 횟수만큼 binary log 쓰기가 발생할 때마다 DB가 binary log 파일의 동기화를 실행
# 설정된 값이 클수록 손실될 수 있는 binary log의 양이 많아지고 binary log의 쓰기 성능은 좋아짐
expire_logs_days = 1 # binary log 보관기간(일), 이 기간이 지나면 자동 삭제
log_bin_trust_function_creators = 1 # Routine 생성자 신뢰, replication 환경에서는 이 설정을 해야만 Routine 생성이 가능함
#binlog-annotate-row-events = ON # 주석도 binary log에 남도록 처리
#sql_log_bin = 0
# mysqld에 적용되는 시스템변수는 아니고, 쓰레드레벨에서 설정할 수 있는 값임
# 해당 쓰레드에서 binary log가 안 남게 하고 싶을 때는 0으로 설정 가능, SUPER 권한 필요함
##---------------------------------------------------------------------------
## Author: YJ
## 슬레이브(Slave) 설정 - replication 환경에서 slave일 때만 의미 있음
##---------------------------------------------------------------------------
#relay_log = /logs001/mysvc01/MARIASVC/relay # 릴레이 로그 경로
#relay_log_purge = TRUE
#read_only # 일기 전용 DB로 설정
##---------------------------------------------------------------------------
## Author: YJ
## 슬레이브(Slave)이면서 마스터(Master)인 경우
##---------------------------------------------------------------------------
#log-slave-updates # 현재 복제되는 쿼리를 바이너리 로그에 저장
##---------------------------------------------------------------------------
## Author: YJ
## mysqld_safe 데몬에만 적용되는 설정
##---------------------------------------------------------------------------
[mysqld_safe]
log-error=/logs001/mysvc01/MARIASVC/error/mysqld.err # 에러로그 파일경로
pid-file = /engn001/mysvc01/MARIASVC/mysqld.pid # 프로세스 ID 파일경로
socket = /engn001/mysvc01/MARIASVC/mysqld.sock # 소켓파일 경로
nice = 0
##---------------------------------------------------------------------------
## Author: YJ
## mysqldump 툴을 이용한 DB 접속시에만 적용되는 설정
##---------------------------------------------------------------------------
[mysqldump]
max-allowed-packet = 1G
default-character-set = 'utf8mb4'
quick # 버퍼를 사용하지 말고, direct로 덤프받기
##---------------------------------------------------------------------------
## Author: YJ
## myisamchk 툴을 이용한 DB 접속시에만 적용되는 설정
##---------------------------------------------------------------------------
[myisamchk]
key-buffer-size = 10M
sort-buffer-size = 10M
read-buffer-size = 8M
write-buffer-size = 8M
##---------------------------------------------------------------------------
## Author: YJ
## mysql 클라이언트 툴을 이용한 DB 접속시에만 적용되는 설정
##---------------------------------------------------------------------------
[mysql]
default-character-set = 'utf8mb4'
no-auto-rehash # 자동 완성 기능 비활성화
local-infile = ON # local file을 이용한 LOAD DATA 작업이 가능하게 함
enable-secure-auth # 서버로 구버전(4.1버전 이하) 포멧으로 된 패스워드 전달 비활성화
prompt=(\U){\h}[\d]\_\R:\m:\\s>\_ # SQL 프롬프트 설정
pager=less -n -i -F -X -E # 데이터 출력시 페이징처리
show-warnings # 경고 발생시 메세지 자동 출력
#safe-updates # 데이터 변경 또는 삭제시 where절을 필수로 갖도록 처리
#i-am-a-dummy
##---------------------------------------------------------------------------
## xtrabackup (innobackupex) 툴을 이용한 DB 접속시에만 적용되는 설정
##---------------------------------------------------------------------------
[xtrabackup]
default-character-set = 'utf8'
# clientlib 5.1로 xtrabackup binary가 build된 경우, 해당 lib에는 utf8mb4가 없어서 아래와 같은 오류가 발생할 수 있음
# 오류내용: "Can't initialize character set utf8mb4"
# lib 5.5로 xtrabackup을 다시 컴파일하면 문제가 없지만 workaround로 위와 같은 옵션을 설정해도 됨
# 위 설정은 특별한 의미는 없으며 lib 5.1에는 utf8이 있기 때문에 오류가 발생하진 않음
##---------------------------------------------------------------------------
## Author: YJ
## 모든 클라이언트 툴을 이용한 DB 접속시에 적용되는 설정
##---------------------------------------------------------------------------
[client]
port = 3306
socket = /engn001/mysvc01/MARIASVC/mysqld.sock
default-character-set=utf8mb4
* 출처 https://good-dba.gitbooks.io/mariadb-installation/content/make_mycnf.html