[NIO] JAVA NIO의 ByteBuffer와 Channel 클래스 사용하기!
기존의 Java IO는 다른 언어에 비해 매우 느리다는 이야기가 많이 있습니다. 내부적으로 어떻게 돌아가는지 대략적으로나마 파악한다면 그럴 수 밖에 없었다는 사실을 알게 되실겁니다. 하지만 jdk1.3부터는 Java IO의 한계를 보완한 Java NIO를 사용하여 I/O에서 속도 향상을 낼 수 있습니다. 그러나 NIO의 사용법은 기존 I/O와는 매우 달라 배우기가 생각만큼 쉽지는 않습니다. 이번 포스팅에서는 Java NIO에 대해 알아보고, 예제를 통해 FileHandling의 Performance를 향상시키는 간단한 예제를 다뤄 NIO에 쉽게 접할 수 있도록 하겠습니다. 생각보다 길어져서 포스팅을 세 개로 나누겠습니다.
- 기존 Java NIO의 단점과 NIO에서 어떻게 단점을 보완했는가? [NIO] JAVA NIO의 ByteBuffer와 Channel로 File Handling에서 더 좋은 Perfermance내기!
- Java NIO의 Class들과 이들의 기본적인 사용법에 대해 알아보자. [NIO] JAVA NIO의 ByteBuffer와 Channel 클래스 사용하기!
- 실제 FileHandling하는 간단한 예제와 실제로 Performance를 비교해보자. [NIO] JAVA NIO와 일반 I/O로 구현한 파일 큐를 이용하여 파일 입출력 Performance 비교!
차근차근 포스팅하도록 하겠습니다. 제가 미흡한 점이 많습니다. 혹시 내용상 오류나 오탈자를 발견하신 분은 바로 댓글로 태클 걸어주시면 감사하겠습니다^^
이전 포스팅에서 기존 Java IO의 단점과 NIO가 이런 단점을 어떻게 보완했는지에 대해서 자세히 알아봤습니다. 이제 실제 NIO 사용방법에 대해 간단히 알아보겠습니다. 사실, 라이브러리의 모든 것을 자세히 알아보다간 포스팅만 길어지고 별로 도움도 안되기 때문에 간단히 사용법만 알아보고 예제 코드를 소개해 보도록 하겠습니다.
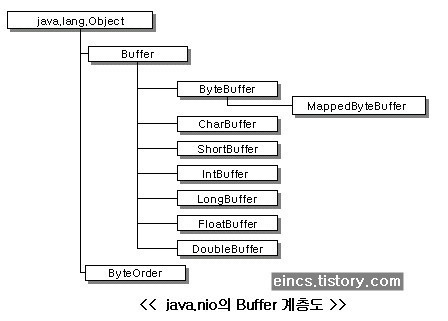
1. NIO의 Buffer클래스¶
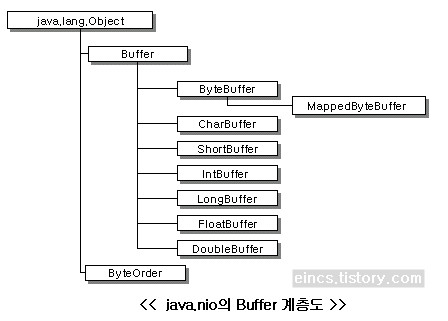
이전 포스팅에서도 말씀드렸지만, NIO에서 지원하는 많은 Buffer 클래스 중 ByteBuffer 클래스만 Direct Buffer를 지원합니다. 다시 말해서, 커널 버퍼에 직접 접근할 수 있는 NIO의 장점을 이용하기 위해서는 ByteBuffer의 allocateDirect()라는 메소드를 이용해서 ByteBuffer를 만들어 내야 합니다. (allocate()메소드를 이용하면 Direct Buffer가 아닌 일반 Buffer가 만들어집니다) 다음을 꼭 기억하도록 합시다!
- ByteBuffer만이 Direct Buffer가 가능!
- ByteBuffer.allocateDirect()메소드를 사용해야 Direct Buffer가 생성됨!
따라서 Direct Buffer, 즉 커널 버퍼를 직접 사용하기 위해서는 CharBuffer와 같은 익숙한 데이터 타입의 Buffer를 이용하지 못하고, 불편하더라도 어쩔 수 없이 ByteBuffer를 이용하여야 합니다. 생각보다 ByteBuffer를 사용하는 것이 어렵진 않으니 걱정하진 마세요.
사실 ByteBufffer나 다른 데이터 타입의 Buffer나 사용법은 매우 비슷하고, NIO를 잘 다루기 위해선 특히 ByteBuffer를 잘 다뤄야 하기 때문에 ByteBuffer를 중점적으로 소개하도록 하겠습니다. 사용법은 대동소이하니 ByteBuffer만 잘 익히신다면 다른 종류의 Buffer를 사용하는 것은 크게 어렵지 않으실겁니다.
1.1. ByteBuffer 생성 방법!¶
ByteBuffer buf1 = ByteBuffer.allocate(10); // direct buffer를 이용하는 것이 아님.ByteBuffer buf2 = ByteBuffer.allocateDirect(10); // 커널 버퍼를 직접 다루는 버퍼!buf2.clear();...
1.2. ByteBuffer의 네 가지 포인터!¶
Buffer 에는 현재 쓰거나 읽을 위치, 유효하게 읽을 수 있는 위치, 현재 용량의 위치 등을 나타내는 포인터가 네가지가 있습니다. position, limit, capacity, mark 로 붙여진 이 네가지 포인터에 대해서 빠삭하게 숙지하고 계셔야 Buffer를 잘 사용하실 수 있습니다. 다음은 이 네 가지 포인터에 대한 간략한 설명입니다.
- **position **: 현재 읽을 위치나 현재 쓸 위치를 가리킵니다. ByteBuffer에서 get()함수로 읽기를 시도할 경우 position위치부터 읽기 시작하며, put()함수로 ByteBuffer에 쓰기를 시도할경우 position 위치부터 쓰기를 시작합니다.. 읽거나 쓰기가 진행될 때마다 position의 위치는 자동으로 이동합니다.
- **limit **: 현재 ByteBuffer의 유요한 쓰기 위치나 유효한 읽기 위치를 나타냅니다. 다시 말해, “이 버퍼는 여기까지 읽을 수 있습니다” 혹은 “여기까지 쓸 수 있습니다”를 나타냅니다. 헷갈리시죠? 자세한 사용법은 아래서 알아보도록 합시다. 다르게 말하면 “여기서부터는 쓸 수 없습니다”, “여기서부터는 읽을 수 없습니다” 라고 표현 가능합니다.
- capacity : ByteBuffer의 용량을 나타냅니다. 따라서, 항상 ByteBuffer의 맨 마지막을 가리키고 있습니다. 그 때문에 position과 limit와는 달리 그 위치랄 바꿀 수가 없죠^^
- mark : 편리한 포인터입니다. 특별한 의미가 있는 것은 아니고, 사용자가 마음대로 지정할 수 있습니다. 특별히 이 위치를 기억하고 있다가 다음에 되돌아가야할 때 사용합니다. 이 포인터에 대해선 차차 사용할 일이 있을 때 사용하실테고, 이 포스팅에선 자세히 다루지는 않겠습니다.
위의 포인터 중 값을 사용자가 지정할 수 있는 position, limit, mark 에는 getter함수와 setter 함수가 있습니다. 특이하게도 일반적인 getter함수와 setter함수와는 다르게 get/set으로 시작하지 않습니다! position의 경우엔 position()이 getter이고, position(int newPosition) 이 setter입니다. limit도 마찬가지입니다만, mark만 좀 다릅니다만, 여기서는 소개하진 안겠습니다.
여튼, 위의 네 가지 포인터간에는 다음과 같은 룰이 적용됩니다.
**0<=mark<=position<=limit<=capacity**
이 룰을 어기면서 position이나 limit, mark를 setter로 강제로 지정한다면 Exception이 발생합니다.
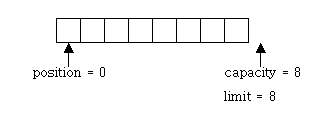
위 그림이 개념도 입니다. 읽거나 쓰기 시작하면 position에서 부터 읽거나 쓰는 것이 발생하죠. 일단 이 부분에 대해서는 그냥 이런게 있구나~하고 넘어가시면 되겠습니다. 직접 사용해보면서 어떤 것인지 알아가는 것이 확실하니까요.
1.3. ByteBuffer에 읽고 쓰기!¶
ByteBuffer 에 읽고 쓰는 함수에는 get()과 put() 이 있습니다. 기본적으로는 byte배열을 읽고 씁니다. 그 외에 putInt(), getInt() 등 다양한 타임에 대한 get/set을 지원합니다. 당연히 int의 경우 4byte를 사용하게 되죠. order()함수로 빅엔디안, 리틀엔디안 방식을 지정할 수 있습니다만, C/C++와는 다르게 java에서는 기본적으로 빅엔디안 방식을 사용하기 때문에 네트워크 프로그래밍을 할 때도 byteOrder를 바꿀 일이 거의 없습니다.
2. NIO의 Channel 클래스¶
NIO의 Channel은 Buffer에 있는 내용을 다른 어디론가 보내거나 다른 어딘가에 있는 내용을 Buffer로 읽어들이기 위해 사용됩니다. 예를 들면 네트워크 프로그래밍을 할 때 Socket을 통해 들어온 내용을 ByteBuffer에 저장하기 위해서나, ByteBuffer로 Packet을 작성 후 Socket으로 흘려 보낼 때 Channel을 사용합니다. 이런 Channel을 ServerSocketChannel 이나 Socket Channel 이라고 합니다. ServerSocketChannel이나 SocketChannel의 경우 Selector를 이용하여 Non-Blocking 하게 입출력을 수행 할 수 있지만, FileChannel은 Blocking만 가능합니다. 이 점은, 운영체제나 시스템 마다 File 입출력시 Non-Blocking을 지원해주지 않는 시스템이 있어 그런 것이라고 합니다. FileChannel은 Blocking 모드만 가능합니다! 이에 관해선 이번에 다루지 않을 Selector와 매우 깊은 관련이 있습니다. 이전 포스팅에 소개해 드렸던 Non-Blocking Server를 만드는 것과 관련이 깊으니 다음에 한번 소개해 보도록 하죠.
일단 지금 관심을 가지고 이야기 할 것은 FileChannel입니다. FileChannel은 바로 File에 있는 내용을 ByteBuffer로 불러오거나 ByteBuffer에 있는 내용을 File에 쓰는 역할을 합니다. 이에 대해서 자세히 알아봅시다. 그전에 꼭 알아야 할것은, Channel은 직접 인스턴스화 할 수가 없다! 입니다. 직접 생성자를 이용해서 인스턴스화하는 것이 아니라, OutputStream이나 InputStream에서 getChannel() 메소드를 이용하여 만들어내야 합니다. 다음을 꼭 기억합시다!
- Channel은 직접 인스턴스화 할 수가 없다!
- OutputStream/InputStream에서 만들어야한다!
FileChannel을 얻는 방법은 다음과 같습니다.
FileInputStream fis = new FileInputStream("test.txt");FileChannel cin = fis.getChannel();FileOutputStream fos = new FileOutputStream("test.txt");FileChannel cout = fos.getChannel();RandomAccessFile raf = new RandomAccessFile("test.txt", "rw");FileChannel cio = raf.getChannel();
위에서 보시는 것과 같이 OutputStream 이나 InputStream을 통해 FileChannel을 얻으실 수 있습니다. 단순히 OutputStream이나 InputStream 외에도 RandomAccessFile과 같이 FileHandling하는 객체에도 getChannel()이라는 메서드가 있다면 FileChannel을 얻을 수 있습니다. FileInputStream이나 OutputStream의 경우, 파일포인터가 읽거나 쓰면 무조건 증가 합니다. 따라서 순차적으로 읽을 때 적당합니다. 하지만 파일 내용을 이리저리 탐색하면서 처리해야할때는 Stream을 이용하면 매우 불편하고 효율적이지도 않습니다. 따라서 이런 경우엔 파일 임의의 지점에서 읽거나 쓸 수 있는 RandomAccessFile 클래스를 이용하여야 합니다. 제세한건 java api문서를 확인합시다!
FileChannel에서 읽고 쓰는 방법은 다음과 같습니다.
FileInputStream fis = new FileInputStream("input.txt");FileOutputStream fos = new FileOutputStream("output.txt");ByteBuffer buf = ByteBuffer.allocateDirect(10);FileChannel cin = fis.getChannel();FileChannel cout = fos.getChannel();cin.read(buf); // channel에서 읽어 buf에 저장!buf.flip();cout.write(buf); // buf의 내용을 channel에 저장!
보시는 것과 같이 ByteBuffer에 있는 내용을 읽고 쓸 수가 있습니다. read함수를 쓰면, position위치에서부터 limit 위치까지의 내용을 FileInputStream의 내용으로 채워 넣습니다. write함수를 쓰면, position위체에서부터 limit위치까지의 내용을 FileOutputStream에 출력합니다. 이미지로 설명하면 다음과 같습니다.
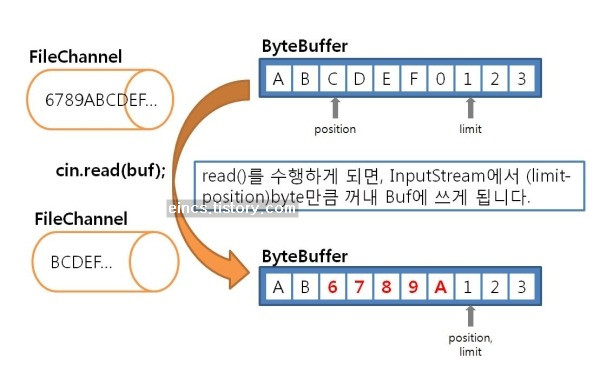
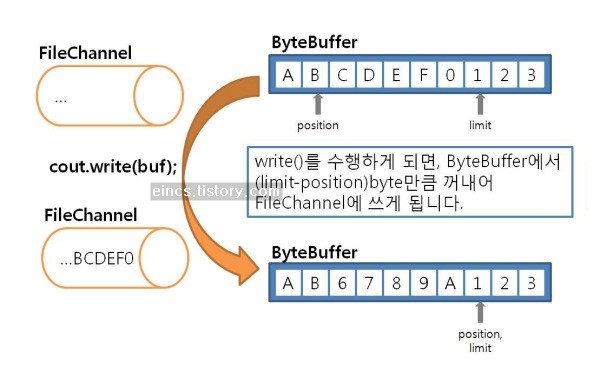
한 가지 의문점이 생겨야 좋은데요, 만약 InputStream으로 만든 FileChannel에서 read를 하지 않고 write를 수행하면 어떻게 될까요? 반대로, OutputStream에서 만들어낸 FileChannel에서 write를 하지 않고 raed를 하는 경우 어떻게 될까요? 위의 경우 Exception이 발생합니다. 한번 확인해 보시구요, 다음을 정리하도록 합시다.
- InputStream으로 만들어낸 FileStream에선 read 만 할 수 있다! (write하는 경우 Exception 발생!)
- OutputStream으로 만들어낸 FileStream에선 write 만 할 수 있다! (read하는 경우 Exception 발생!)
이건 FileChannel을 만들어낼때 사용한 객체의 특성때문이라고 생각하시면 될 것 같습니다.
그런데, RandomAccessFile의 경우에는 어떨까요. RandomAccessFile은 seek로 탐색한 파일포인터 위치에서 읽거나 쓸 수 있는 객체입니다. 당연하게도, read/wrtie 모두 수행 가능합니다. 하지만 seek으로 설정한 파일포인터 부터 읽거나/쓰기가 가능합니다.
3. ByteBuffer와 Channel 을 이용한 File 읽고 쓰기¶
간단하게 RandomAccessFile과 ByteBuffer, FileChannel을 이용하여 File의 읽고 쓰기의 방법에 대해 알아보겠습니다. 다음 코드를 보시죠.
RandomAccessFile raf = new RandomAccessFile("sample.txt", "rw");FileChannel channel = raf.getChannel();ByteBuffer buf = ByteBuffer.allocateDirect(10);buf.clear();raf.seek(10); // 파일의 10째 바이트로 파일포인터 이동channel.read(buf); // channel에서 읽어 buf에 저장!buf.flip();raf.seek(40); // 파일의 40째 바이트로 파일포인터 이동channel.write(buf); // buf의 내용을 channel에 저장!channel.close();raf.close();
위 프로그램의 내용은, sample.txt에 있는 내용중 10번째 바이트부터 10개의 바이트를 읽어 ByteBuffer에 저장 후, 방금 읽어드린 10개의 바이트를 파일의 40번째 바이트부터 출력하는 예제입니다. 매우 간단한 프로그램 이지만, 이부분만 잘 이해하신다면 FileChannel을 이용하여 더 빠른 File 입출력을 구현하시는데에는 큰 어려움이 없으실 겁니다. 참고로 덧붙여서 말씀드리면, 실제로 그냥 byte배열을 이용하는 것보다 위 프로그램이 좀 더 좋은 퍼포먼스를 보여줍니다.
위에서 쓴 함수 중, clear()함수는 당연히 아시겠고, flip()함수는 ByteBuffer에 저장한 후 그 데이터를 읽기 위해서 반드시 써줘야 하는 함수입니다. limit를 현재 position으로 설정한 후, position을 0으로 설정하는 함수인데, 그 원리를 잘 생각해보세요. flip()을 쓰지 않으면 position이 쓰기를 마친 지점에 그대로 있습니다. 이럴 경우 buffer에서 read를 수행하면 방금 write 한 것이 읽혀지는게 아니라 쓰고난 다음 index부터 읽혀집니다.